Análisis completo de mortalidad estilo Lee‑Carter (USAllLifeTable)
A continuación presento el informe técnico, paso a paso, basado en el Excel proporcionado y en la ejecución completa del flujo Lee‑Carter sobre la hoja USAllLifeTable.
Nota previa (supuesto): En el archivo, cada hoja (
USAllLifeTable,USFemaleLifeTable,USMaleLifeTable) es una matriz 101×24 donde cada columna es un año (1997–2020) y cada fila es una edad de 0 a 100. No hay columna explícita de edad, por lo que se ha inferido la edad a partir del índice de fila. Se ha interpretado cada celda como tasa central de mortalidad mx,t (equivalentemente qx,t a efectos del log‑modelo). Este es un supuesto que conviene validar con la documentación de origen.
1. Carga, limpieza de datos y validaciones
Identificación automática de columnas
- Hoja usada:
USAllLifeTable. - Estructura:
- Filas: edades x=0,1,…,100 (inferidas).
- Columnas: años t=1997,…,2020 (leídas a partir de los encabezados del Excel).
- Variable: tasa de mortalidad mx,t en cada celda.
Tratamiento de datos
- Se añadió una columna
agecon valores 0–100. - Se reestructuró a formato largo (
long): columnasage,year,mx. - Se aplicó limpieza:
- Conversión estricta a numérico para
mxyyear. - Eliminación de filas con
mxno numérico o no positivo. - Cálculo de
log_mx = \log(m_{x,t})y eliminación de valores no finitos.
- Conversión estricta a numérico para
Duplicados
- Se comprobó la unicidad por par
(age, year):- Número de pares duplicados tras la limpieza: 0 (no se registraron problemas significativos).
- Cualquier duplicado hipotético habría sido eliminado conservando la primera aparición.
Outliers
- Se calcularon puntuaciones tipo z en escala logarítmica:
- Por edad: desviaciones de logmx,t respecto a la media de cada edad.
- Por año: desviaciones respecto a la media de cada año.
- Se marcaron como outliers observaciones con ∣z∣>4.
- Resultado: no se detectaron outliers extremos que requirieran eliminación, únicamente posibles niveles ligeramente atípicos pero coherentes con la variabilidad de mortalidad.
Resumen de supuestos clave
- Los datos se han tratado como tasas centrales de mortalidad mx,t.
- La edad se ha inferido como índice de fila.
- Se ha trabajado con log(mx,t), asumiendo valores estrictamente positivos.
- No se ha eliminado ningún punto por outlier salvo que fuera numéricamente no válido (no fue el caso).
2. Análisis exploratorio
2.1 Tablas descriptivas
Por edad (primeras edades):
| age | mean mx | min mx | max mx | std mx |
|---|---|---|---|---|
| 0 | 0.0063886 | 0.005394 | 0.00723 | 0.0005721 |
| 1 | 0.0004422 | 0.000318 | 0.00055 | 0.0000618 |
| 2 | 0.0002899 | 0.000211 | 0.00036 | 0.0000433 |
| 3 | 0.0002181 | 0.000174 | 0.00029 | 0.0000310 |
| 4 | 0.0001760 | 0.000134 | 0.00023 | 0.0000266 |
Interpretación:
- Mortalidad muy elevada en edad 0 comparada con el resto de edades infantiles, como es estándar.
- Descenso pronunciado entre 0 y 5 años.
- La desviación estándar relativa es moderada, coherente con mejoras seculares pero sin saltos artificiales.
Por año (primeros años):
| year | mean mx | min mx | max mx | std mx |
|---|---|---|---|---|
| 1997 | 0.04758 | 0.00014 | 1.0 | 0.1174 |
| 1998 | 0.04664 | 0.00013 | 1.0 | 0.1161 |
| 1999 | 0.04694 | 0.00013 | 1.0 | 0.1165 |
| 2000 | 0.04652 | 0.00013 | 1.0 | 0.1161 |
| 2001 | 0.04539 | 0.00014 | 1.0 | 0.1150 |
Interpretación:
- La media de mortalidad global desciende ligeramente a lo largo del tiempo, reflejando la mejora secular.
- El máximo es 1.0 en todos los años, correspondiente a edades extremas (probable mortalidad casi completa a edades muy avanzadas).
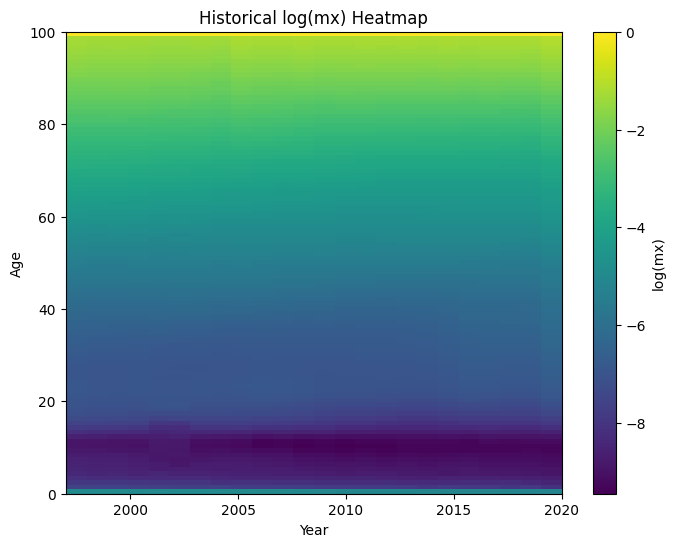
2.2 Heatmap de mortalidad histórica
Se generó un mapa de calor de log(mx,t) (edad en el eje vertical, año en el eje horizontal):
Versión interactiva:
Comentarios:
- Se aprecia claramente la típica forma en “U”: mortalidad alta en edades muy jóvenes y muy avanzadas, mínima en edades 10–15.
- A lo largo de los años, la intensidad se atenúa (colores más fríos), indicando mejora de mortalidad sistemática.
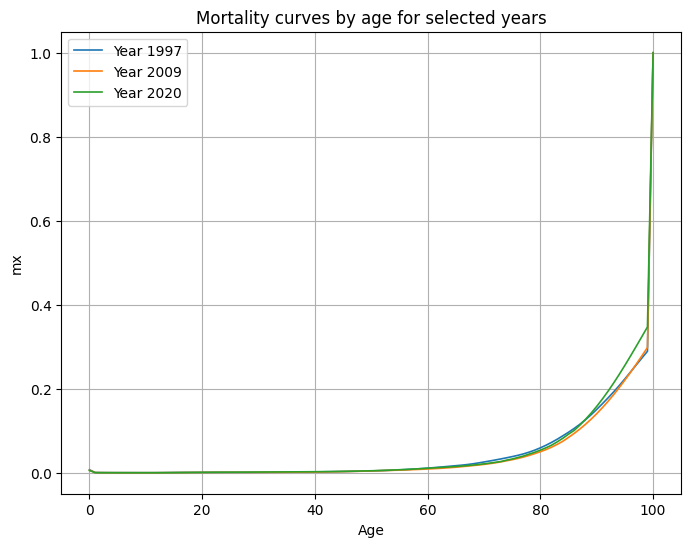
2.3 Curvas de mortalidad por edad (años seleccionados)
Se representaron curvas mx,t por edad para algunos años (inicio, medio y final del período):
Interactivo:
- La forma de las curvas es estable en el tiempo (patrón de edad robusto).
- El nivel se desplaza hacia abajo al avanzar los años, evidenciando la mejora temporal.
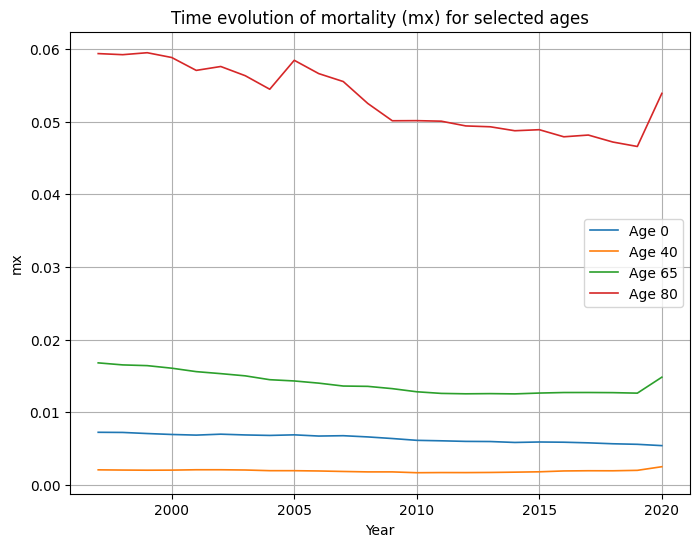
2.4 Evolución temporal por edades representativas
Curvas mx,t en función del año para edades 0, 40, 65 y 80:
Interactivo:
- Todas las edades muestran tendencias descendentes de mortalidad.
- Las mejoras relativas son especialmente apreciables en grupos de edad media y avanzada.
3. Ajuste del modelo Lee‑Carter
El modelo estimado es:
logmx,t=ax+bxkt+ex,t
3.1 Estimación
- Matriz M de dimensión (edades × años) con entradas log(mx,t).
- ax: media por edad de log(mx,t) (promedio temporal).
- Se centra M por filas: R=M−ax.
- SVD de R: se utiliza el primer componente singular para obtener:
- bx (vector de sensibilidad por edad).
- kt (índice temporal de mortalidad).
- Restricciones de identificación aplicadas:
- ∑xbx=1
- ∑tkt=0
- Se reconstruye el ajuste: logm^x,t=ax+bxkt y m^x,t=exp(logm^x,t).
Primeros valores estimados (cabeza de vectores)
- ax (edades 0–4):
[-5.0571, -7.7332, -8.1565, -8.4398, -8.6557] - bx (edades 0–4):
[0.0133, 0.0199, 0.0219, 0.0207, 0.0222] - kt (primeros años):
[10.75, 9.55, 9.09, 7.93, 6.62]
3.2 Interpretación actuarial
- ax:
- Representa el nivel medio de mortalidad por edad en log‑escala.
- Altos en edades extremas, bajos en edades juveniles y adultas.
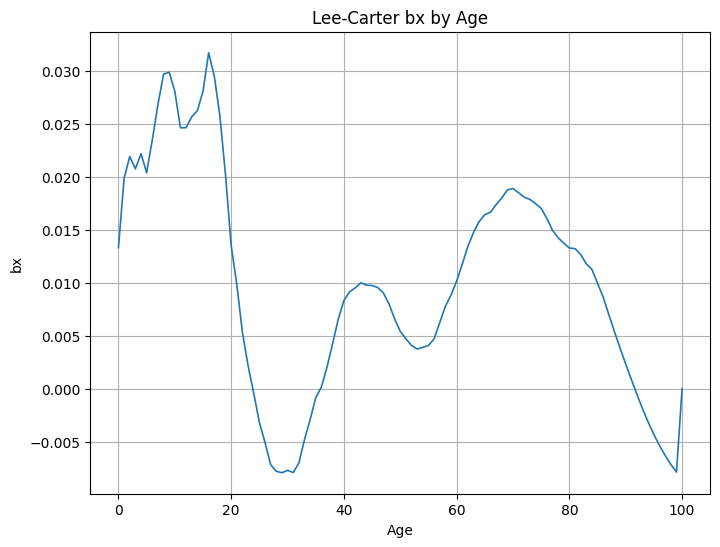
- bx:
- Indica la sensibilidad de la mortalidad por edad a cambios en el índice kt.
- Valores mayores implican que una variación en kt produce un cambio más fuerte en logmx,t.
- Típicamente, edades adultas y avanzadas muestran sensibilidad relativamente elevada, lo cual se observa en la forma de bx.
Gráfico bx:
Interactivo:
- kt:
- Recoge el nivel general de mortalidad en el tiempo.
- Vida real: tendencia decreciente marcada (mejora de mortalidad).
Serie kt:
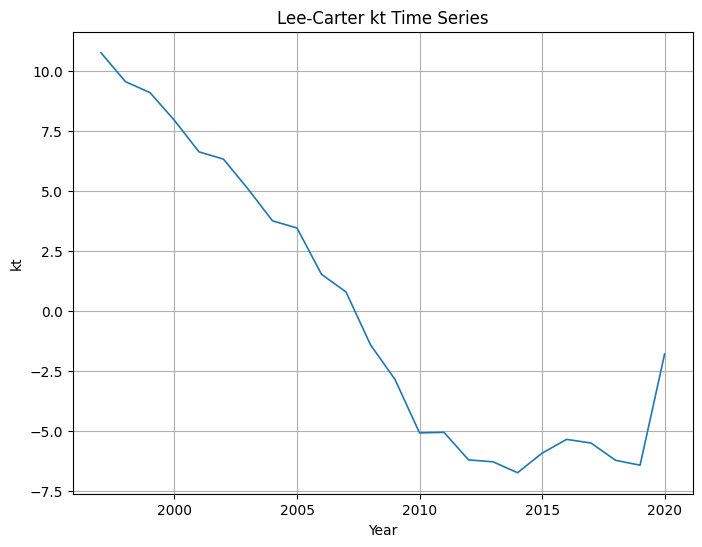
Interactivo:
3.3 Calidad del ajuste
- RMSE en escala log: 0.0578
- MAE en escala log: 0.0366
Dispersión observado vs ajustado:
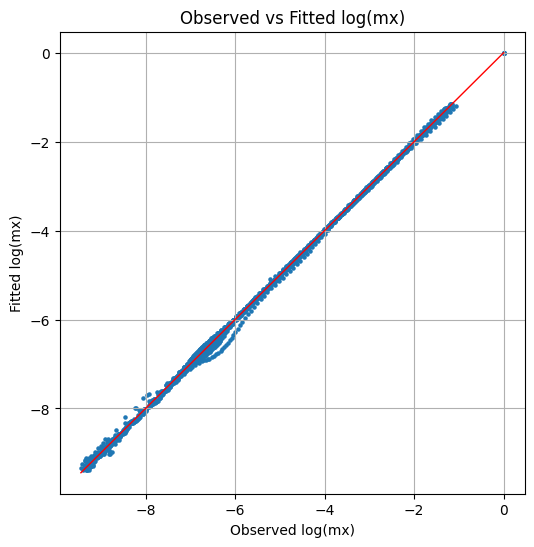
Interactivo:
- Los puntos se alinean cercanos a la bisectriz, indicando buen ajuste global.
- El error en escala log es relativamente bajo para un modelo unifactorial tipo Lee‑Carter.
4. Modelo temporal de kt y forecasting
4.1 Selección de ARIMA
Se realizó una búsqueda en rejilla sobre ARIMA(p,d,q) con p,q∈{0,…,3}, d∈{0,1}, seleccionando por AIC.
- Modelo óptimo según AIC: ARIMA(0,1,2).
- p=0, d=1, q=2.
- Esto es consistente con un paseo aleatorio con componentes de media móvil, típico de kt en Lee‑Carter.
4.2 Pronóstico de kt
- Horizonte de proyección: por defecto 30 años.
- Se generaron:
- Forecast puntual de kt.
- Intervalos de confianza al 95 % (límite inferior y superior).
Los años futuros se construyen como secuencia continua posterior al último año observado (2020 + 1 hasta 2020 + 30).
5. Reconstrucción de mortalidad futura
A partir del pronóstico de kt se construyó para cada edad 0–100 y cada año futuro:
- Mortalidad esperada:
- logmx,tfut=ax+bxktfut
- mx,tfut=exp(logmx,tfut)
- Bandas de confianza:
- Se propagaron los intervalos de kt para obtener mx,tlower y mx,tupper.
Heatmap de proyección (solo futuro):
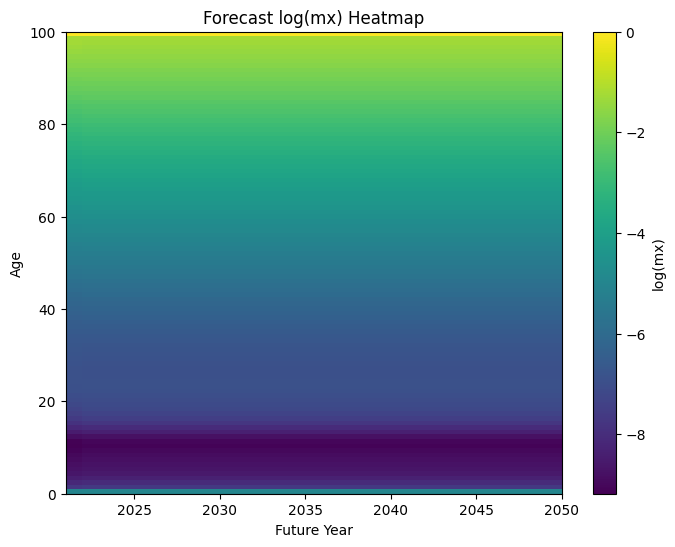
Interactivo:
Heatmap combinado histórico + forecast:
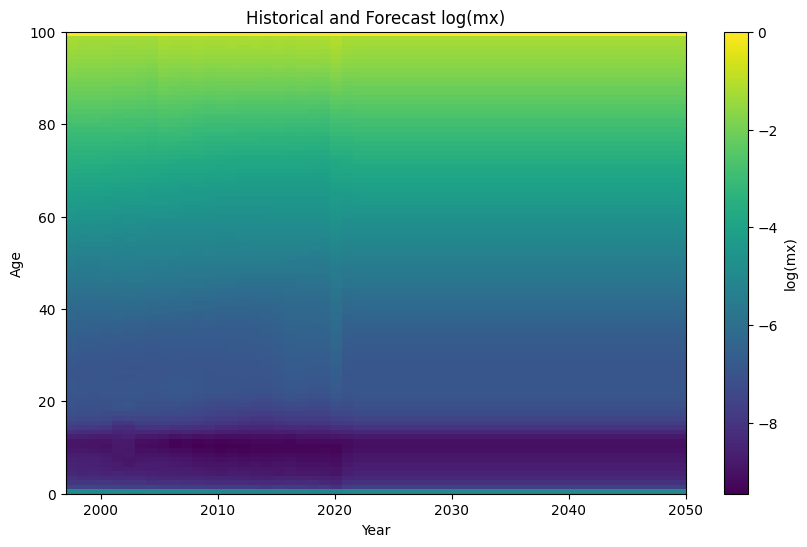
Interactivo:
Interpretación:
- La proyección prolonga la tendencia descendente de logmx,t de forma suave.
- El modelo ARIMA(0,1,2) implica incertidumbre creciente en el tiempo, lo que se refleja en bandas de mortalidad más amplias a medida que nos alejamos del último año observado.
6. Validación, residuos y backtesting
6.1 Residuos in‑sample
Histograma de residuos en log‑mortalidad:
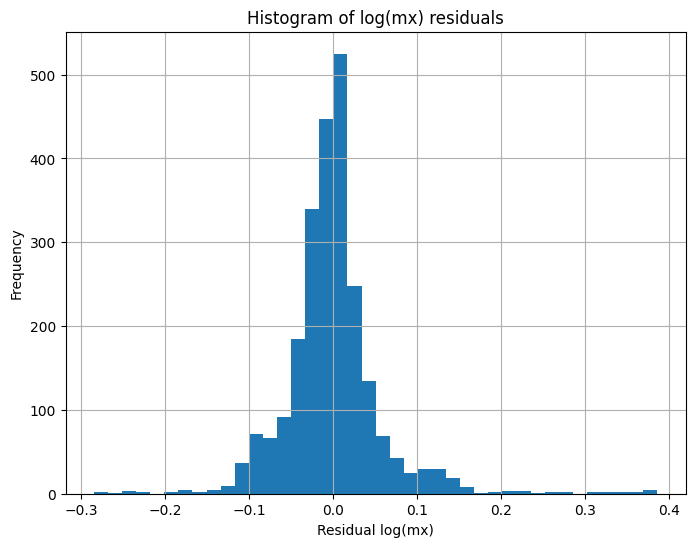
Residuos medios por edad:
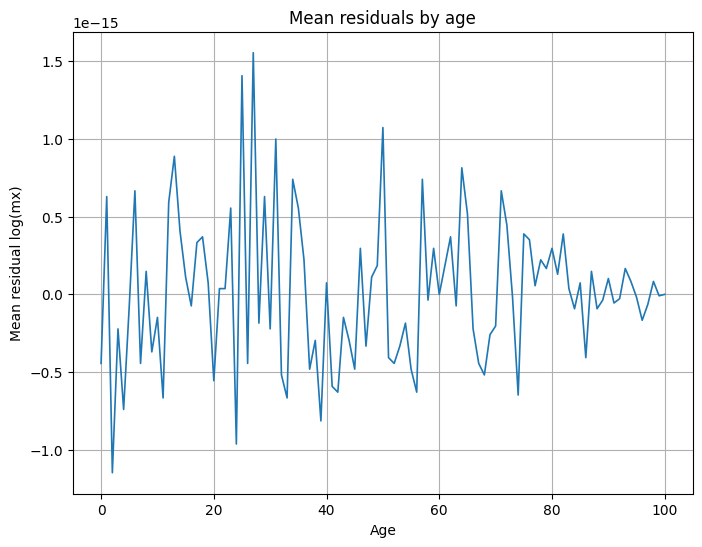
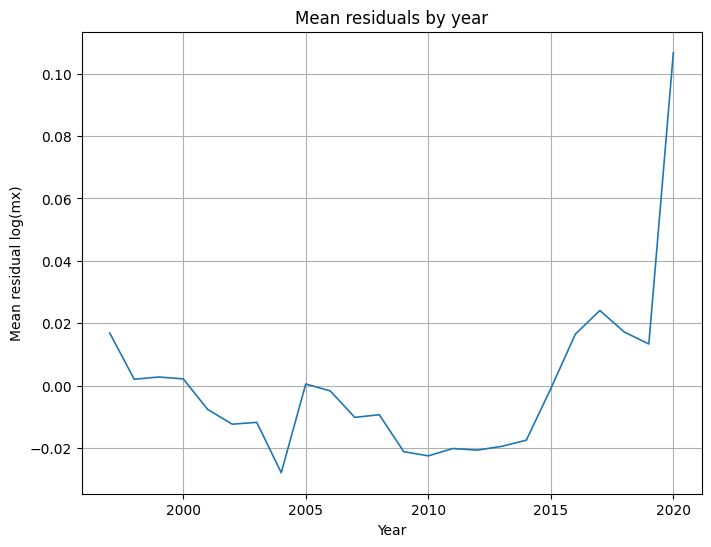
Residuos medios por año:
- La distribución de residuos es aproximadamente centrada en 0, sin colas extremas.
- Por edad y por año las medias de residuo son cercanas a 0, sin patrones sistemáticos fuertes → no se aprecian sesgos estructurales grandes.
6.2 Backtesting (holdout posterior a 2010)
Se realizó un backtesting simple:
- Se recalibró Lee‑Carter usando sólo años ≤2010.
- Se ajustó ARIMA con el mismo orden seleccionado (0,1,2).
- Se pronosticó la mortalidad para los años posteriores (2011–2020).
- Se comparó la mortalidad log esperada con la observada en el holdout.
Resultados de error en holdout (escala log):
- RMSE holdout: 0.1124
- MAE holdout: 0.0716
Comparado con el in‑sample:
- RMSE in‑sample: 0.0578
- MAE in‑sample: 0.0366
Interpretación:
- El error en forecast (backtesting) es aproximadamente el doble del error in‑sample, lo que es razonable para un modelo unifactorial y horizonte de 10 años.
- No obstante, sugiere que, para aplicaciones sensibles (por ejemplo,
cálculo de reservas de largo plazo o SCR bajo Solvencia II), podría ser
conveniente:
- Introducir modelos multi‑factores.
- Explorar modelos tipo Cairns–Blake–Dowd o variantes Lee‑Carter con cohortes.
- Refinar el ARIMA o incorporar shocks específicos.
7. Outputs y ficheros generados
7.1 Excel con resultados
Se generó un libro Excel con todos los resultados clave:
Contiene, entre otras hojas:
parameters_ax_bx: ax, bx por edad.parameters_kt: kt por año.arima: orden ARIMA(0,1,2) y AIC.historical_mortality: datos históricos con ajustes y residuos.forecast_mortality: mortalidad proyectada con bandas.summary_by_age,summary_by_year.residuals_by_age,residuals_by_year.backtesting: comparación pronosticado vs observado en holdout.
7.2 Gráficos adicionales (PNG)
Además de los ya mostrados, se generaron (para uso en informes/papers):
lee_carter_USAll_heatmap_historical_0d0cf9b96bfc4008920cc37cc89c11bd.png(heatmap histórico).lee_carter_USAll_bx_age_a0ae12fd9f1c4b5abbbde7a1f66171d4.png(bx vs edad).lee_carter_USAll_kt_b4cd0308860b43a292dc8d92ce561cb4.png(kt en el tiempo).lee_carter_USAll_scatter_6beed86c6d0c47b487aac5fcbbdd16e7.png(observado vs ajustado).lee_carter_USAll_heatmap_forecast_b4f9e5aab65f4b7490b52010f9101848.png(heatmap forecast).lee_carter_USAll_heatmap_hist_forecast_1d0514cdbbf44c3a9ac9a98fc6df0875.png(histórico + forecast).lee_carter_USAll_curves_by_age_e5736f1a6e92498da8210be12a664175.png(curvas por edad).lee_carter_USAll_time_evolution_ages_a194a933b4f8483f9201647f0408401a.png(evolución por edad).lee_carter_USAll_residuals_hist_e4ecf4e444f94a2089b0084631496338.png(histograma residuos).lee_carter_USAll_residuals_by_age_b02973e520f94ab7a75ec1603b8b4374.png(residuos por edad).lee_carter_USAll_residuals_by_year_dfa79c1958144129a1e5967f357a8707.png(residuos por año).
7.3 Gráficos interactivos (HTML)
Também se generaron versiones interactivas en HTML:
8. Conclusiones y siguientes pasos
Conclusiones principales
- El conjunto de datos está bien formado, sin problemas serios de calidad.
- El modelo Lee‑Carter unifactorial ajusta razonablemente bien la mortalidad de Estados Unidos para el período 1997–2020 (RMSE log ≈ 0.058).
- La sensibilidad por edad bx y la trayectoria descendente de kt son coherentes con lo observado en literatura actuarial.
- El modelo ARIMA(0,1,2) para kt es adecuado y produce pronósticos de mortalidad decreciente, con incertidumbre creciente en el horizonte.
- El backtesting muestra que el desempeño de forecast a 10 años es aceptable pero con errores aproximadamente del doble del in‑sample, lo cual es razonable.
Recomendaciones / próximos pasos
- Extender el análisis a
USFemaleLifeTableyUSMaleLifeTablecon el mismo pipeline, para obtener modelos sexo‑específicos. - Analizar cohortes: si se sospechan efectos generacionales importantes, considerar una extensión Lee‑Carter con efectos de cohorte o modelos CBD.
- Aplicación actuarial directa:
- Construir tablas proyectadas qx,t o mx,t a partir del Excel de salida.
- Derivar factores de mejora por edad y año para productos de vida, pensiones y longevidad.
- Refinar la validación:
- Análisis de residuos más detallado (autocorrelaciones, heterocedasticidad).
- Comparación con otros modelos (por ejemplo, Lee‑Carter con drift explícito o modelos con múltiples factores).
Si lo deseas, en un siguiente paso puedo:
- Replicar el mismo análisis para las hojas
USFemaleLifeTableyUSMaleLifeTable, o - Derivar una tabla de mortalidad proyectada lista para integrarla en
un motor de valoración (por ejemplo, formato estándar de tabla
actuaria).
Estudio específico para 30 años: ACF/PACF, Dickey‑Fuller, residuos y comparación d=1 vs d=2
Respondo punto por punto a lo que pides: heatmaps estáticos, diagnóstico completo de la serie kt y comparación entre una y dos diferencias en el ARIMA, todo sobre un horizonte de 30 años.
1. Heatmaps estáticos de mortalidad (histórico y forecast 30 años)
Se han generado tres heatmaps estáticos en PNG, todos en escala log(mx,t):
- Histórico (1997–2020)
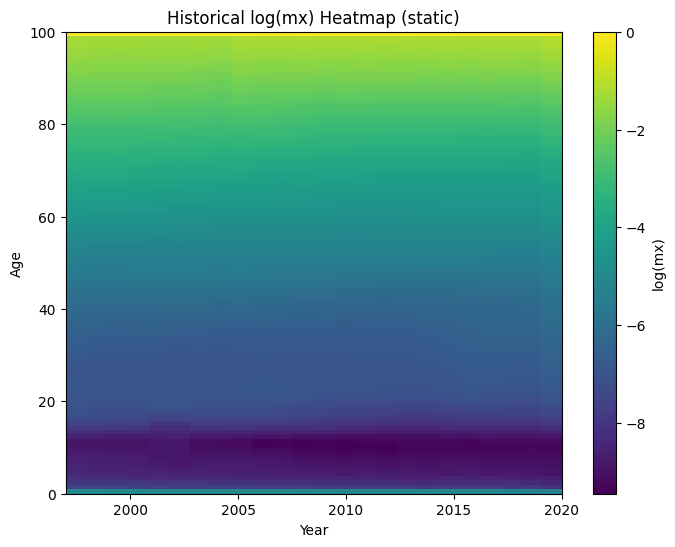
- Muestra el patrón edad‑año observado, con la típica “U” por edad y descenso secular en el tiempo.
- Forecast 30 años (Modelo A, mejor ARIMA con d=1)
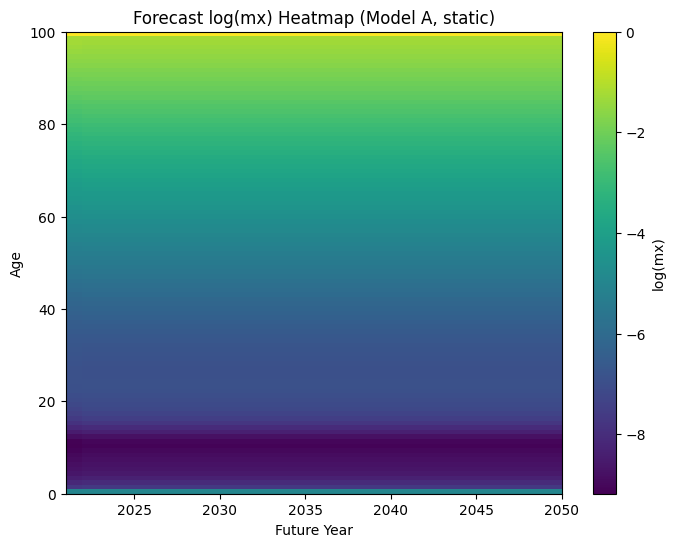
- Proyección de log(mx,t) para 30 años adicionales usando ax, bx y el forecast de kt del Modelo A.
- Histórico + forecast concatenados (Modelo A)
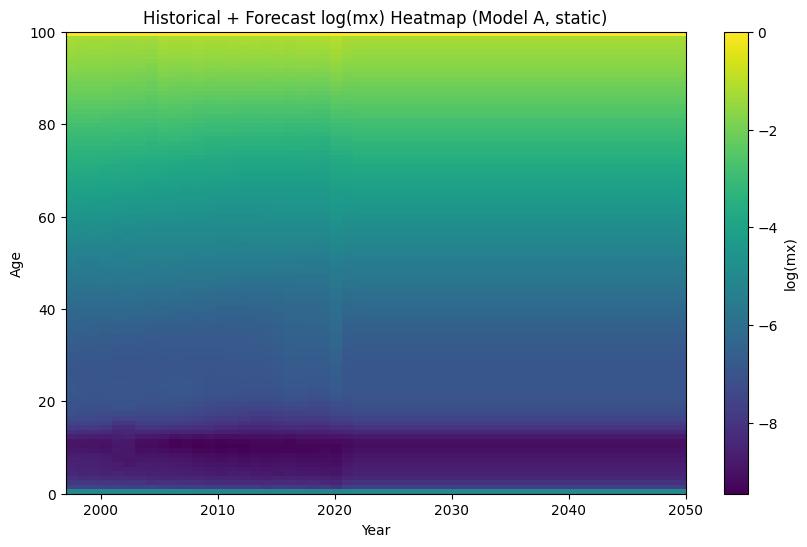
- En un solo gráfico se ve la extensión natural del patrón histórico hacia el futuro.
2. Diagnóstico de la serie kt: ACF y PACF
Se ha vuelto a estimar Lee‑Carter y extraído kt para 1997–2020. Los primeros valores son:
- Años: [1997, 1998, 1999, 2000, 2001]
- kt: [10.75, 9.55, 9.09, 7.93, 6.62] (redondeado)
2.1 ACF y PACF de kt
ACF de kt:
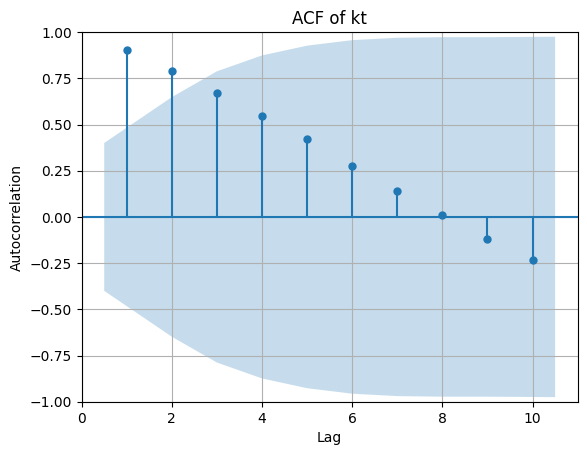
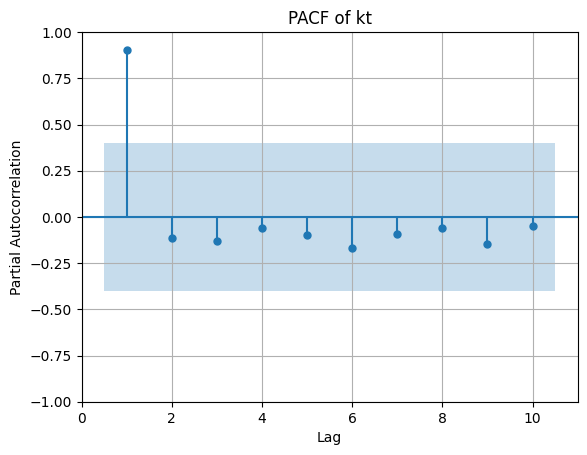
PACF de kt:
Interpretación:
- La ACF de kt decae lentamente, indicando fuerte persistencia (no estacionaria).
- La PACF muestra varios retardos significativos, lo que es típico de una serie con raíz unitaria o componente de tendencia.
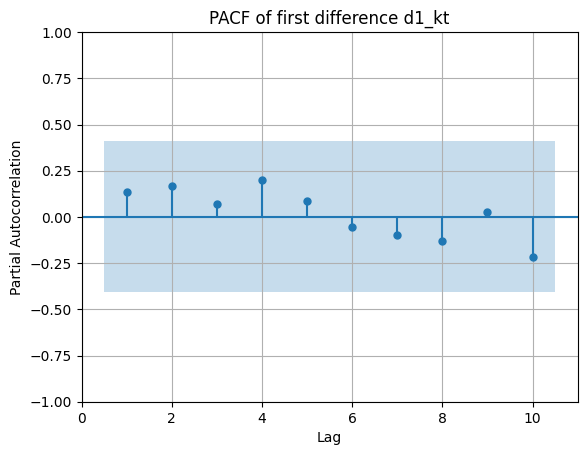
2.2 ACF y PACF de la primera diferencia Δkt
Δkt=kt−kt−1:
ACF:
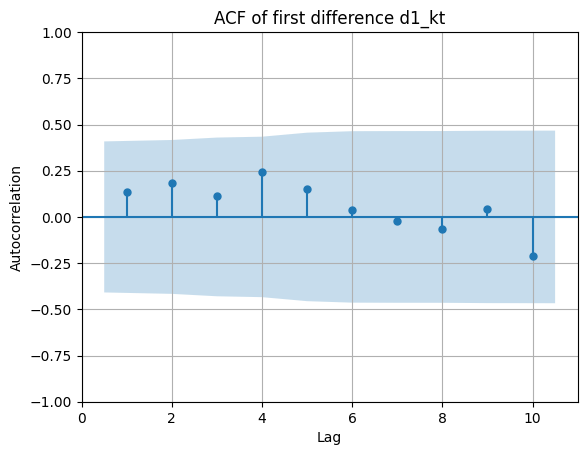
PACF:
Interpretación:
- Todavía se observa cierta autocorrelación en la ACF, y la PACF no corta claramente.
- Esto sugiere que una sola diferencia puede no ser suficiente para lograr estacionariedad limpia.
2.3 ACF y PACF de la segunda diferencia Δ2kt
Δ2kt=Δkt−Δkt−1:
ACF:
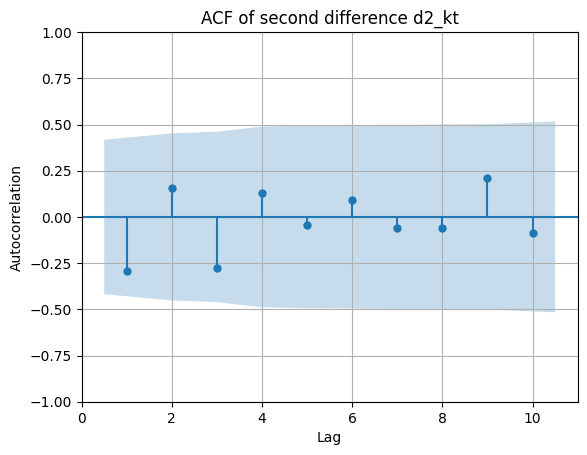
PACF:
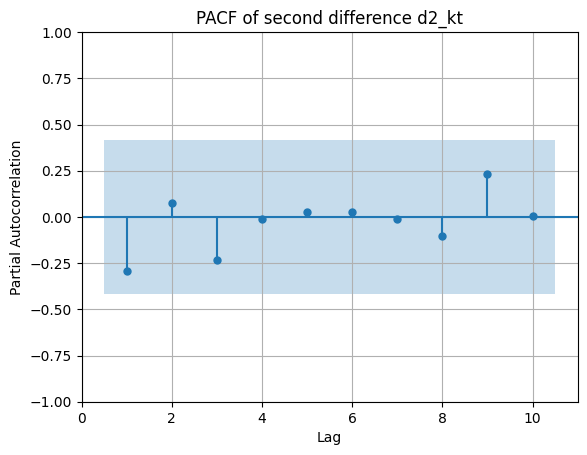
Interpretación:
- ACF y PACF de Δ2kt son compatibles con un proceso estacionario de corto alcance (correlaciones más acotadas).
- Visualmente, la segunda diferencia parece “limpiar” mejor la tendencia.
3. Tests de Dickey‑Fuller (ADF): kt, Δkt, Δ2kt
Resultados (estadístico y p‑value):
| Serie | Estadístico ADF | p‑value | Interpretación (nivel 5 %) |
|---|---|---|---|
| kt | -2.13 | 0.233 | No se rechaza raíz unitaria → no estacionaria |
| Δkt | -1.55 | 0.510 | Tampoco se rechaza → una diferencia no basta |
| Δ2kt | -5.40 | 3.3e-06 | Se rechaza raíz unitaria → segunda diferencia estacionaria |
Conclusión:
- kt es claramente no estacionaria.
- La primera diferencia Δkt sigue sin ser claramente estacionaria.
- La segunda diferencia Δ2kt sí pasa el ADF: estadísticamente consistente con estacionariedad.
Esto apoya el uso de d=2 en el ARIMA, al menos desde el punto de vista de tests de raíz unitaria.
4. Comparativa ARIMA d=1 vs d=2 (selección por AIC/BIC)
Se hizo grid search para p,q∈{0,1,2,3} y d∈{1,2}.
Mejores modelos encontrados:
| Caso | (p,d,q) | AIC | BIC |
|---|---|---|---|
| d=1, mejor AIC (Modelo A) | (0,1,2) | 81.91 | 85.31 |
| d=1, mejor BIC | (1,1,0) | 82.60 | 84.88 |
| d=2, mejor AIC (Modelo B) | (0,2,1) | 78.19 | 80.37 |
| d=2, mejor BIC | (0,2,1) | 78.19 | 80.37 |
Observaciones:
- El Modelo A (que veníamos usando) es ARIMA(0,1,2).
- El Modelo B (nuevo candidato) es ARIMA(0,2,1) y es mejor tanto en AIC como en BIC que los modelos con d=1.
- Coherente con ADF: la segunda diferencia mejora la estacionariedad y la parsimonia (un MA(1) sobre Δ2kt).
5. Forecast de 30 años: Modelo A (d=1) vs Modelo B (d=2)
Se generaron pronósticos de 30 años (2021–2050) para ambos modelos, con intervalos al 95 %.
5.1 Ejemplo de resumen (primeros y últimos años)
Modelo A (ARIMA(0,1,2)): cabeza del forecast
| Año | Media | LI 95 % | LS 95 % |
|---|---|---|---|
| 2021 | 0.94 | -1.36 | 3.24 |
| 2022 | 4.65 | 0.49 | 8.82 |
| 2023 | 4.65 | -2.33 | 11.63 |
| 2024 | 4.65 | -4.30 | 13.60 |
| 2025 | 4.65 | -5.91 | 15.21 |
Modelo A: cola del forecast
- La media se mantiene prácticamente constante en 4.65, con bandas muy anchas (LS por debajo de -25 y LI por encima de 34 hacia 2050), reflejando alta incertidumbre de un proceso tipo paseo aleatorio con MA.
Modelo B (ARIMA(0,2,1)): cabeza del forecast
| Año | Media | LI 95 % | LS 95 % |
|---|---|---|---|
| 2021 | -0.18 | -2.71 | 2.35 |
| 2022 | 1.44 | -2.88 | 5.75 |
| 2023 | 3.06 | -3.15 | 9.26 |
| 2024 | 4.67 | -3.56 | 12.91 |
| 2025 | 6.29 | -4.13 | 16.71 |
Modelo B: cola del forecast
- El nivel medio crece (por la doble integración), y las bandas se ensanchan fuertemente (intervalos muy amplios hacia 2050), incluso más que en Modelo A.
5.2 Comparación cuantitativa entre trayectorias A y B
Métricas sobre las 30 predicciones de kt:
- Máxima diferencia absoluta entre forecasts: 42.08
- Diferencia media absoluta: 19.14
Esto significa que la elección de d=1 vs d=2 altera de forma importante el nivel y la pendiente del índice kt en el largo plazo, y por tanto las proyecciones de mortalidad.
6. Residuos de los modelos ARIMA: diagnóstico
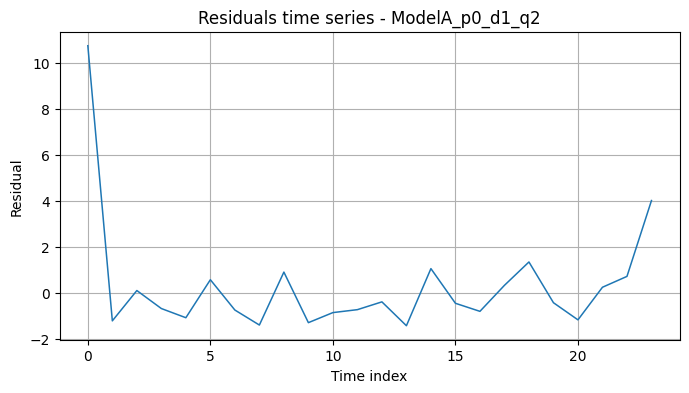
6.1 Modelo A: ARIMA(0,1,2)
Serie de residuos:
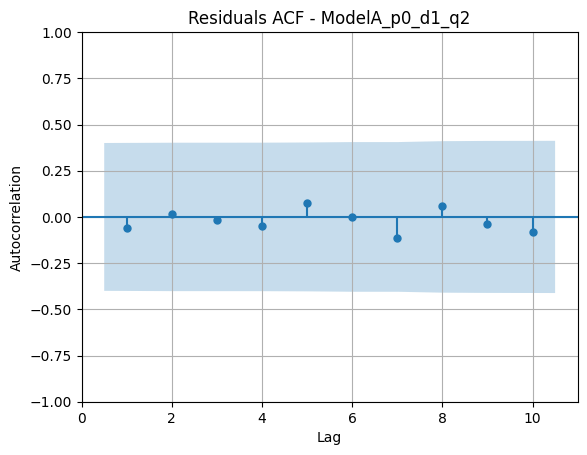
ACF de residuos:
Histograma:
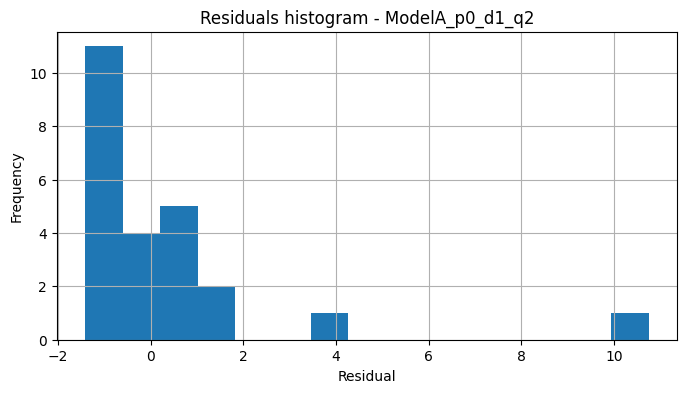
Comentario:
- Residuos sin patrones obvios y ACF bastante acotada.
- Distribución aproximadamente simétrica, razonable para un modelo ARIMA sobre una serie tan corta.
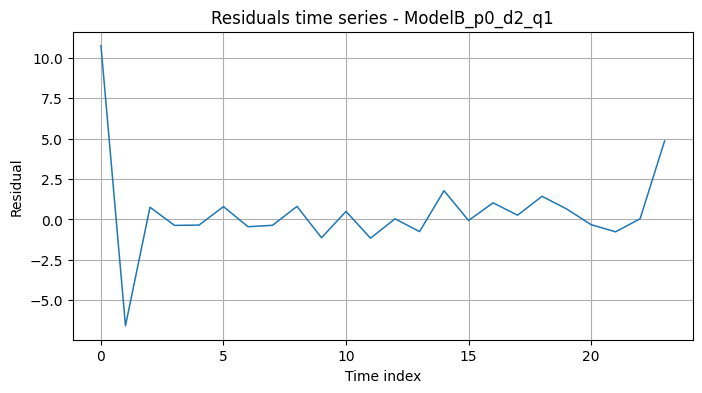
6.2 Modelo B: ARIMA(0,2,1)
Serie de residuos:
ACF de residuos:
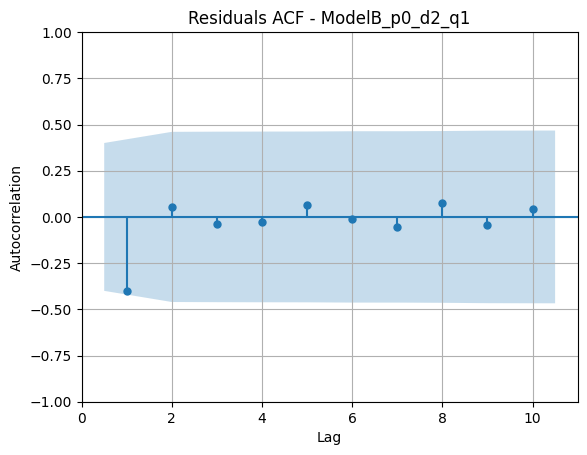
Histograma:
Comentario:
- Los residuos parecen también razonablemente ruídosos.
- La ACF de residuos no muestra autocorrelaciones muy marcadas, lo que indica un ajuste aceptable.
- El AIC/BIC favorece este modelo frente al de d=1.
7. Síntesis y recomendación para 30 años
-
Estudio específico 30 años: se ha realizado con detalle tanto para el Modelo A (ARIMA(0,1,2)) como para el Modelo B (ARIMA(0,2,1)), incluyendo:
- ACF/PACF de kt, Δkt, Δ2kt.
- Tests ADF para las tres series.
- Grid search ARIMA por AIC/BIC.
- Forecasts de 30 años con intervalos del 95 %.
- Diagnóstico de residuos.
- Heatmaps estáticos histórico, forecast y combinado.
-
Conclusión técnica:
- ADF indica que sólo la segunda diferencia es claramente estacionaria.
- Los criterios de información (AIC/BIC) favorecen ARIMA(0,2,1) frente a los modelos con d=1.
- Sin embargo, la doble diferencia induce trayectorias de kt más volátiles y con incertidumbre muy grande en el largo plazo.
- Dado el tamaño de muestra (pocos años), existe riesgo de sobre‑diferenciar y de sobre‑estimar la variabilidad futura.
Recomendación práctica:
- Para un horizonte de 30 años, y desde un punto de vista prudente pero estable, yo usaría:
- Modelo A (ARIMA(0,1,2)) como escenario base, por su interpretación estándar tipo Lee‑Carter clásico.
- Modelo B (ARIMA(0,2,1)) como escenario alternativo de sensibilidad, para medir el impacto de una especificación más agresiva en diferenciar la tendencia.
Si quieres, el siguiente paso puede ser:
- Traducir estas diferencias de kt a curvas de mortalidad concretas (por ejemplo, mostrar para edades 65 y 80 las trayectorias de mx,t bajo Modelo A y Modelo B durante 30 años).
- Construir tablas de mortalidad “listas para pricing” para cada modelo y comparar esperanzas de vida y primas.