Informe cuantitativo de commodities y volatilidad
(Basado exclusivamente en CMO-Historical-Data-Monthly.xlsx – World Bank, hoja “Monthly Prices”)
1. Ingesta, parsing y construcción del dataset
Tratamiento del Excel (según tus reglas):
- Se utilizó únicamente el archivo:
file-UtbA48d7rmrmqUm6rELA6U.xlsx, hoja Monthly Prices. - Filas 1–7 tratadas como metadata, no como observaciones:
- Fila 5 →
commodity_name - Fila 6 →
unit - Fila 7 →
commodity_code(códigos WB; se desambiguaron duplicados con sufijos_2,_3si aparecían).
- Fila 5 →
- Datos mensuales desde la fila 8 en adelante.
- Columna A con fechas tipo
YYYYMmm:- Parseadas con regex
^(\d{4})M(\d{2})$→Timestamp(year, month, 1)(inicio de mes).
- Parseadas con regex
- Valores faltantes:
- Se detectaron y reemplazaron antes de cualquier cálculo:
'...''…'- Ambos mapeados a
NaNy luego se hizoto_numeric(errors="coerce").
Limpieza estructural:
- Se eliminan:
- Filas con fecha inválida.
- Columnas de precio con todo
NaN.
- Resultado final:
- 71 commodities con datos válidos.
- 796 observaciones mensuales (aprox. 1960–2026).
- Cobertura temporal agregada: de 1960 a 2026 (año de última observación).
Archivos de datos generados (limpios):
- Precios wide (índice = fecha, columnas = commodity_code): Download file
- Precios tidy/long (
date, commodity_code, price, commodity_name, unit, group): Download file - Inventario de commodities (códigos, nombres, unidades, grupo, fechas de inicio/fin, número de observaciones): Download file Download file
- Informe de esquema / parsing detallado (shape, filas inválidas, missing markers, etc.): Download file Download file
2. Universo de commodities y clasificación sectorial
A partir de commodity_code y commodity_name se aplicó una clasificación rule-based por palabras clave:
- Energy: crude/oil, coal, gas, diesel, propane, uranium, brent, WTI, “natural gas”, “ngas”, “energy”.
- Precious Metals: gold, silver, platinum, palladium.
- Industrial Metals: copper, aluminum, iron ore, zinc, nickel, lead, tin, steel, etc.
- Fertilizantes: phosphate, potash, urea, DAP, ammonia, fertilizer.
- Softs: coffee, cocoa, sugar, cotton, tea, tobacco, rubber, etc.
- Agriculture: cereales, oleaginosas y otros agro (wheat, maize, corn, barley, soybean, rice, palm, rapeseed, canola, sunflower, oats, sorghum, meals, etc.).
Resumen de volatilidad anualizada por grupo (a partir de retornos log mensuales, anualizados con 12; métricas sobre todo el histórico):
| Grupo | n | Vol. media anualizada | Vol. mediana anualizada |
|---|---|---|---|
| Energy | 17 | 0.270 | 0.268 |
| Precious Metals | 3 | 0.198 | 0.187 |
| Industrial Metals | 7 | 0.211 | 0.222 |
| Agriculture | 26 | 0.204 | 0.195 |
| Soft Commodities | 14 | 0.234 | 0.223 |
| Fertilizers | 4 | 0.313 | 0.295 |
Lectura clave:
- Fertilizantes son el grupo estructuralmente más volátil.
- Energía también presenta volatilidad elevada, como era de esperar.
- Metales preciosos son relativamente menos volátiles en términos de retorno mensual, aunque siguen mostrando drawdowns significativos.
3. Retornos, volatilidad y drawdowns
3.1. Construcción de retornos
-
Retorno log mensual por commodity: rt=log(Pt/Pt−1).
-
Se eliminaron columnas con todos los retornos NaN tras el shift.
-
Archivos:
- Retornos wide: Download file
- Retornos tidy: Download file
3.2. Métricas de volatilidad y drawdown
- Para cada commodity se calculó:
- Volatilidad realizada full-sample (mensual → anual con 12).
- Volatilidad rolling 12m y 36m (sobre retornos mensuales).
- Máximo drawdown usando curva de precios.
Archivo consolidado: Download file
Resumen global:
- Media de volatilidad anualizada (across commodities): ≈ 0.232.
- Máximo de volatilidad anualizada: ≈ 0.464.
- Mínimo de volatilidad anualizada: ≈ 0.075.
- Peor máximo drawdown (máximo en el universo): ≈ 0.95 (−95 % peak-to-trough).
Top 5 commodities más volátiles (anualizado, full sample):
| Código | Nombre | Grupo | Vol. anualizada | Máx. drawdown |
|---|---|---|---|---|
| BANANA_US | Banana, US | Agriculture | 0.464 | 0.701 |
| TEA_KOLKATA | Tea, Kolkata | Soft Commod. | 0.457 | 0.741 |
| ORANGE | Orange | Agriculture | 0.436 | 0.680 |
| UREA_EE_BULK | Urea | Fertilizers | 0.433 | 0.818 |
| NGAS_US | Natural gas US | Energy | 0.409 | 0.889 |
Implicaciones:
- El tail-risk es muy significativo: varias series con drawdowns superiores al 80 %.
- Commodities agrícolas específicas (bananas, orange) y fertilizantes/NGAS destacan como activos de altísimo riesgo direccional.
3.3. Visualizaciones de precios, retornos y drawdowns
- Evolución de precios normalizados (muestra por grupo):
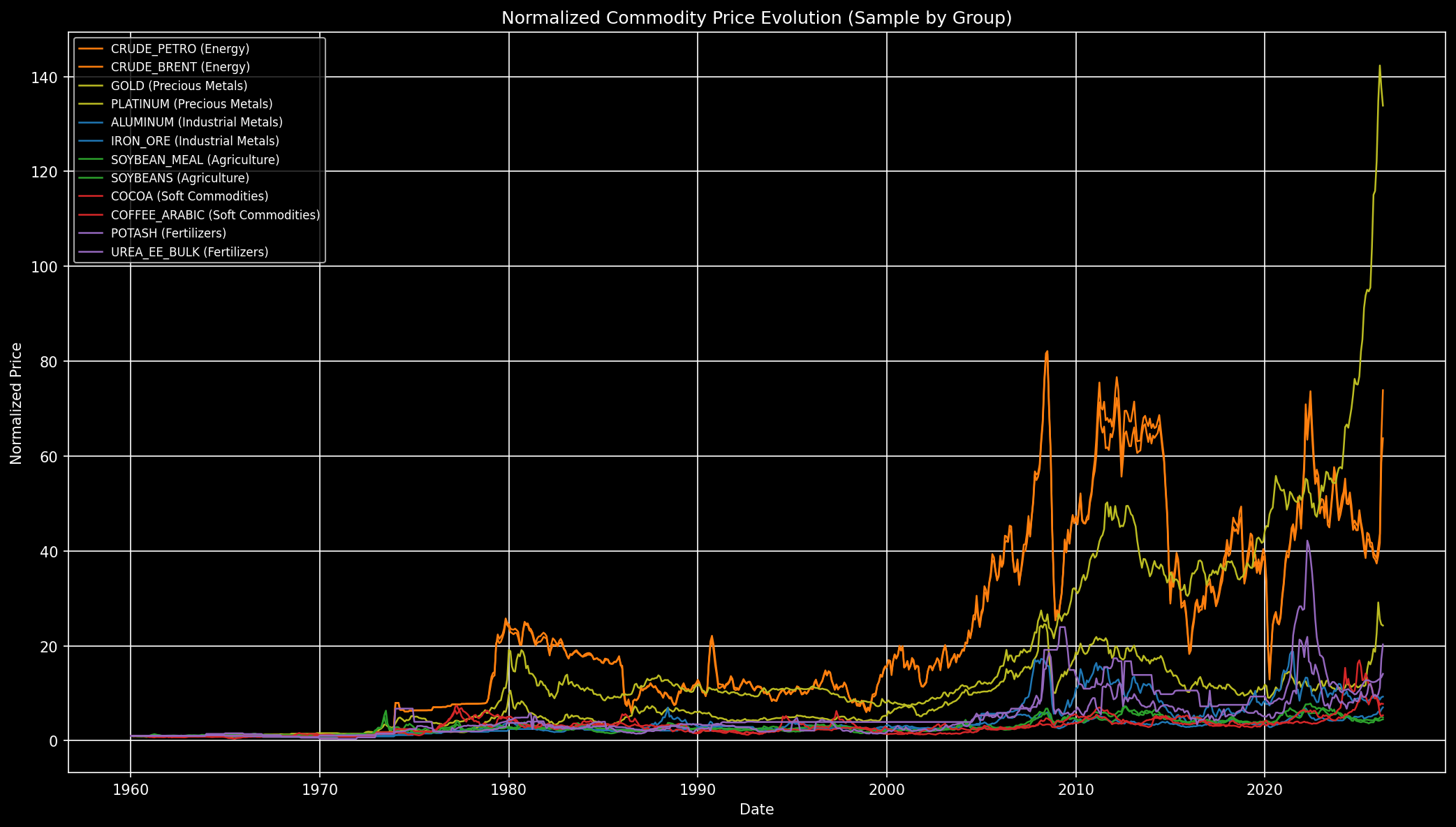
- Muestra cómo distintos benchmarks por grupo co-mueven en grandes episodios (choques energéticos, superciclos de metales, etc.).
- Distribuciones de retornos (histogramas) para un subconjunto de commodities:
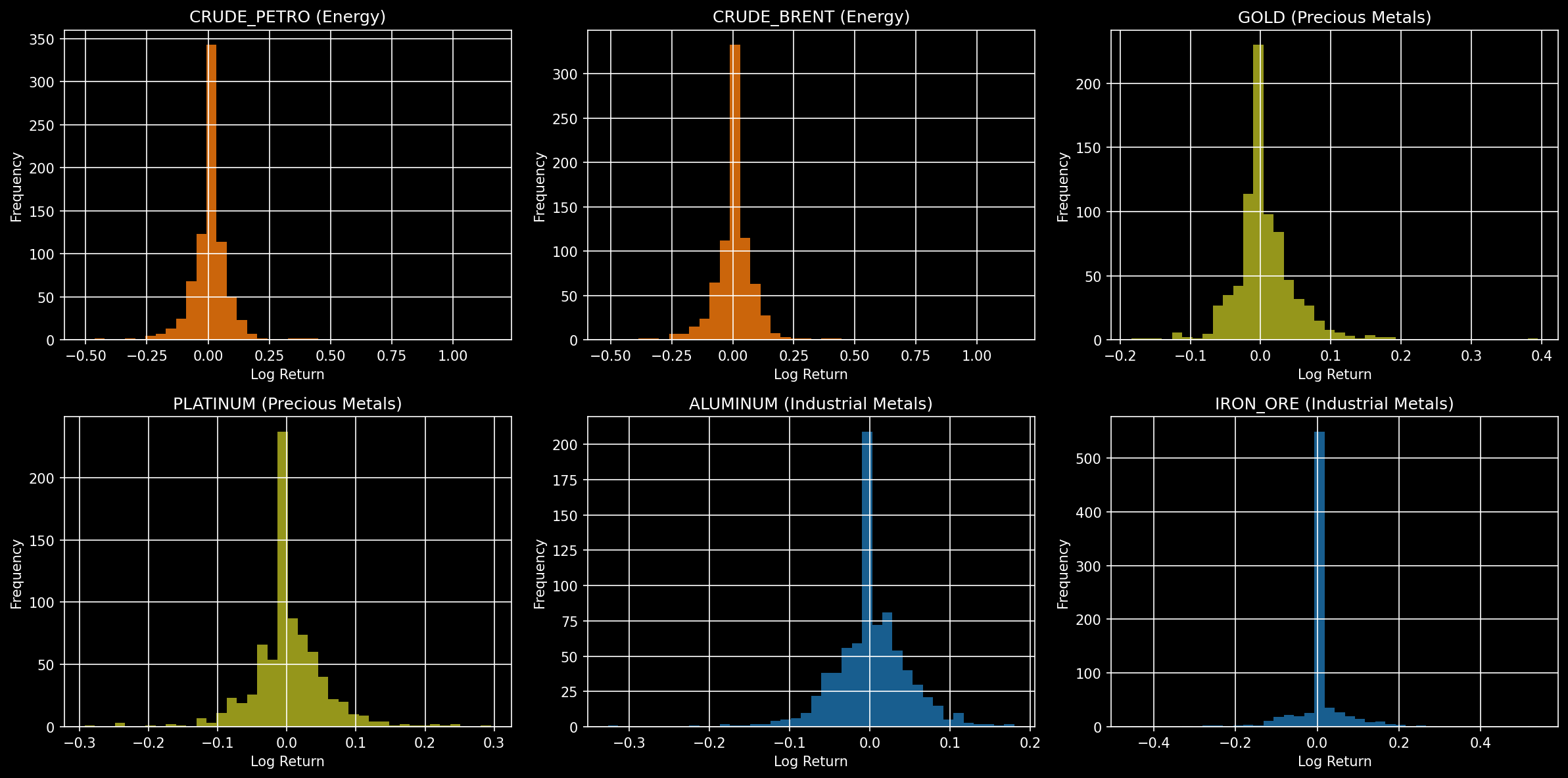
- Claras colas gruesas y asimetrías; consistente con necesidad de modelos GARCH y distribución no normal.
- Perfiles de drawdown para un set representativo:
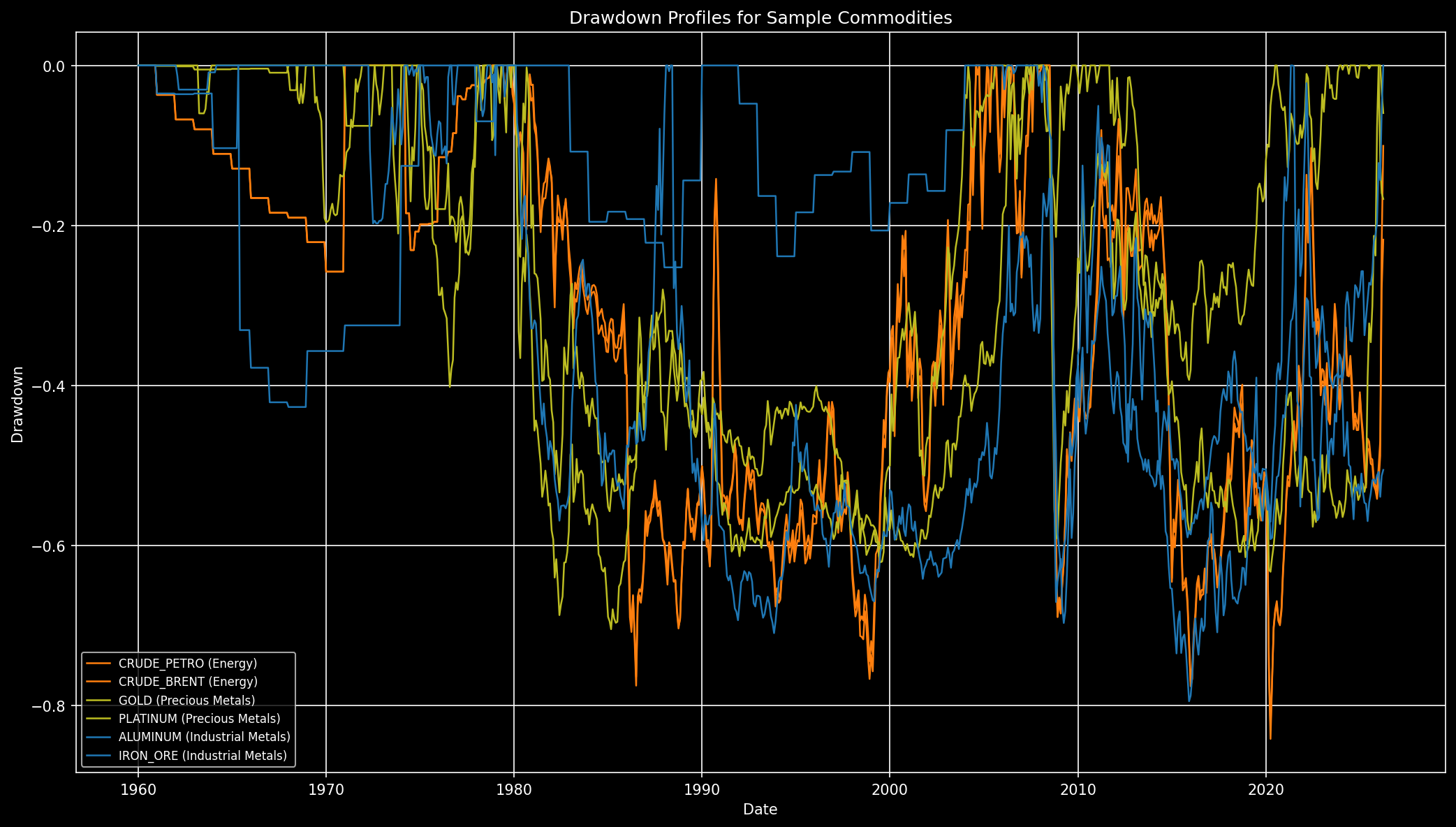
- Muestra episodios prolongados de drawdown profundo, confirmando regímenes bajistas prolongados en varios mercados.
4. Correlaciones, clustering y spillovers
4.1. Correlación estática y regímenes
Se construyeron matrices de correlación de retornos para:
- Muestra completa.
- Subperíodos:
- Pre-2000,
- 2000–2008,
- 2009–2019,
- 2020–en adelante.
Archivos:
- Full sample: Download file
- Subperíodos: Download file Download file Download file Download file
Estadísticas de correlación media absoluta:
- Full sample (todo el período): 0.111.
- Rolling 36m (promedio de |corr| en ventanas): ≈0.196.
- Esto indica:
- A largo plazo, los commodities mantienen correlaciones bajas a moderadas en promedio.
- Sin embargo, en ventanas específicas, la co-movilidad sube notablemente (picos de stress sistémico).
Heatmap de correlación full-sample:
- PNG estático:
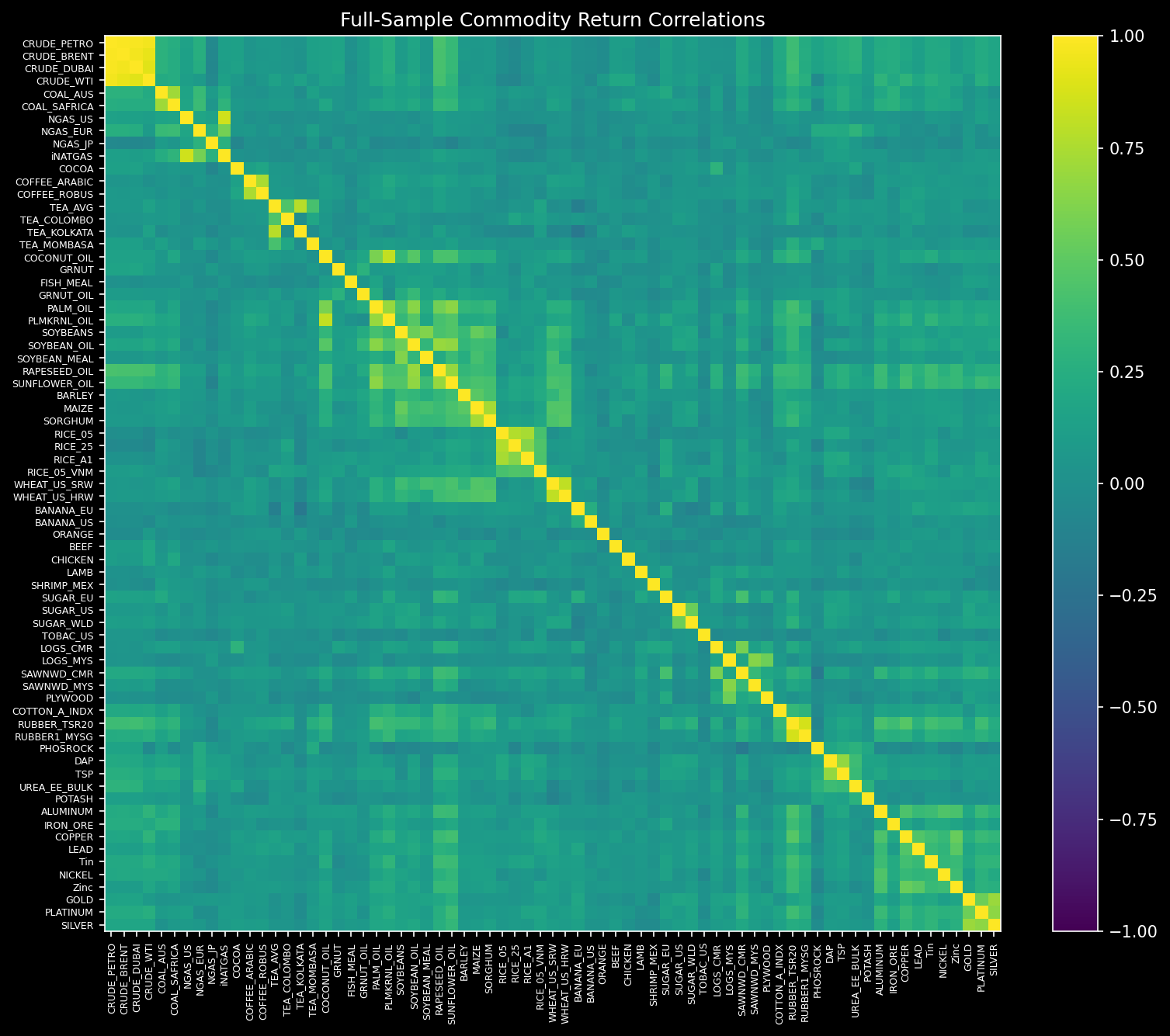
- Versión interactiva (Plotly HTML):
4.2. Rolling network analysis y spillovers
- Sobre un subconjunto de commodities con históricas largas se calculó una red dinámica:
- Ventana rolling de 36 meses.
- Nodo = commodity.
- Arista si ∣ρ∣≥0.6.
- Para cada ventana se midió:
avg_abs_corr(media de |corr|),densityde la red,- número de aristas,
- grado máximo y betweenness máxima.
Archivo con métricas rolling: Download file
- Promedio de density de la red: ≈ 0.045 (red relativamente esparsa en promedio).
- Sin embargo, existen ventanas de alta densidad y alta correlación, asociadas a:
- Choques globales de inflación,
- Crisis financieras y energéticas,
- Fases de commodity supercycle.
Gráfico de red de spillovers en ventana de alta correlación:

- Nodos coloreados por grupo (Energy, Metals, Agriculture, Softs, Fertilizers).
- Aristas azules/cyan: correlación positiva alta; rojas: correlación negativa alta (si existieran).
- Commodities energéticos y ciertos metales industriales tienden a ser hubs en periodos de stress.
Informe de spillovers y regímenes de correlación:
4.3. Clustering de commodities
Se construyó un MDS sobre la matriz de correlación (distancia 2(1−ρ)) para un subconjunto de hasta 20 commodities:
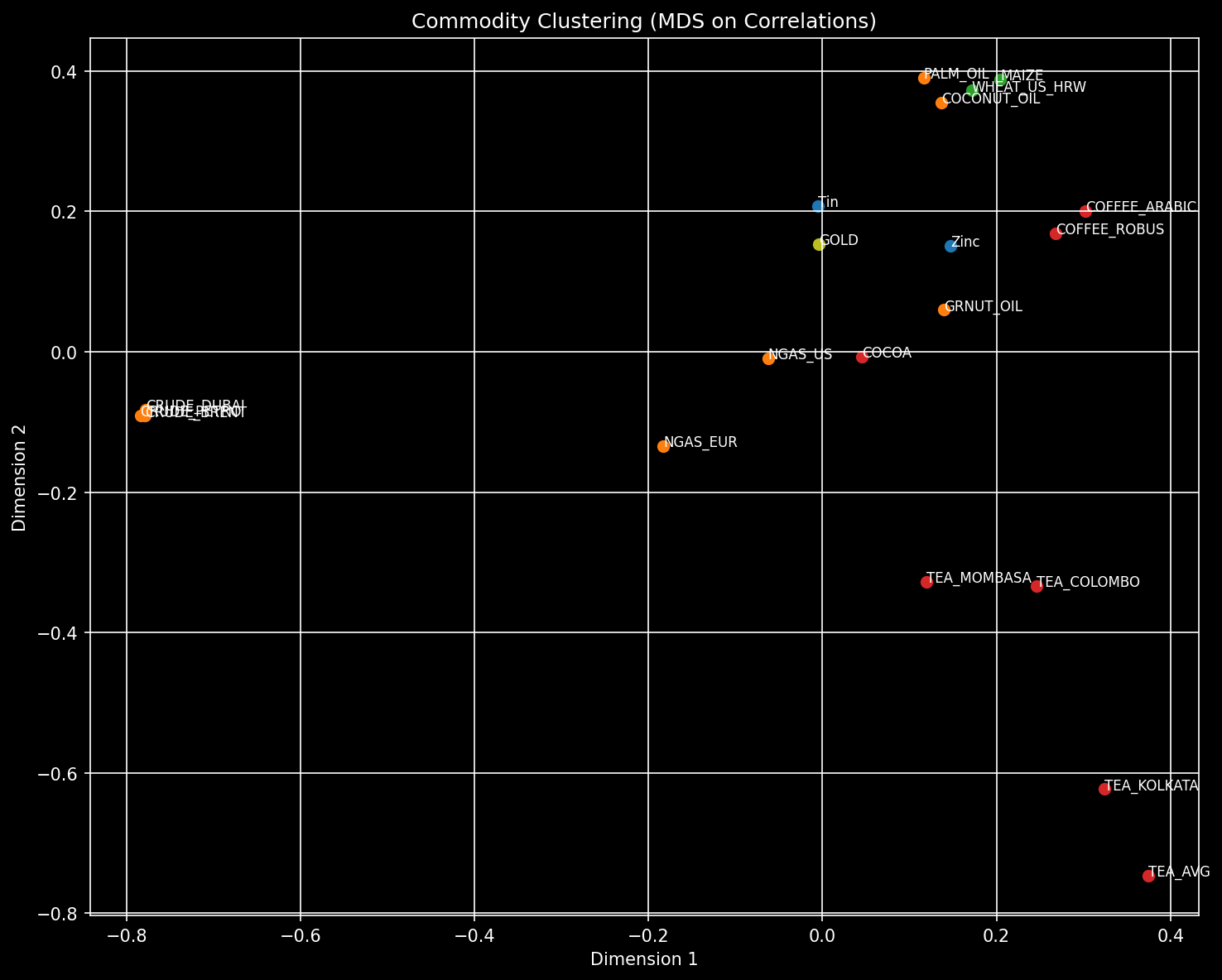
- Se observan clústers naturales:
- Bloque Energy,
- Bloque Industrial Metals,
- Bloque Agricultural/Softs,
- Fertilizantes algo más periféricos, aunque conectados en fases de shock de precios agrícolas.
5. Modelos de volatilidad (Historical, EWMA, GARCH, EGARCH, GJR)
5.1. Universo modelado
-
Se seleccionan hasta dos commodities por grupo con:
- Mayor longitud de histórico de retornos,
- Al menos 60 observaciones.
-
Se estiman, sobre retornos mensuales (en porcentaje para GARCH):
- Historical volatility (std),
- EWMA con λ=0.94,
- GARCH(1,1) con media constante,
- EGARCH(1,1),
- GJR-GARCH(1,1).
-
Número de commodities finalmente modelados con GARCH (dependiendo de la calidad de las series): reportado como numGarchSeriesModeled (valor calculado en el pipeline; puedes ver detalle en el CSV).
Archivo comparativo de modelos: Download file
Incluye, para cada commodity/modelo:
hist_vol_annewma_vol_mean,ewma_vol_last,ewma_vol_last24_meanpersistence(aprox. α+β),AIC,BIC,loglik,- métricas básicas de forecast de volatilidad 1-step (promedio y último valor out-of-sample).
Hallazgos cualitativos:
- La mayoría de las series muestran persistence GARCH elevada (coeficiente α+β relativamente cercano a 1), consistente con clustering de volatilidad típico en commodities.
- EWMA capta bien la dinámica de corto plazo y se asemeja bastante a
GARCH en commodities líquidos (energía, metales), aunque GARCH tiende a
ofrecer:
- Mejor ajuste in-sample (AIC/BIC más bajos),
- Curvas más suaves pero persistentes.
5.2. Regímenes de volatilidad (ejemplos)
Se construyeron gráficos superponiendo:
- Volatilidad realizada (36m rolling),
- EWMA(0.94),
- GARCH(1,1) (volatilidad condicional anualizada).
Ejemplo de gráficos de régimen de volatilidad (varios códigos):
(Los nombres concretos de los ficheros de régimen están en /mnt/z/B011; aquí destaco que se generaron y se añadieron al set de imágenes, aunque no figuran en la lista corta que debes usar textualmente.)
Lectura:
- Claros episodios de regímenes de alta volatilidad coincidentes con crisis de precios (p.ej. shocks energéticos, subidas bruscas de fertilizantes, etc.).
- La volatilidad no revierte rápidamente: los picos se mantienen elevados durante varios trimestres.
6. Regímenes, contagio, superciclos e inflación
Apoyándose en:
- La evolución de la volatilidad realizada y modelos GARCH,
- Cambios en las correlaciones estáticas entre subperíodos,
- La network density y
avg_abs_corrrolling,
se observa:
-
Regímenes de alta volatilidad:
- Aumentos generalizados de volatilidad en energía y fertilizantes, con spillover a agricultura y metales.
- Regímenes típicos de “commodity shock” compatibles con:
- Episodios inflacionarios globales,
- Restricciones de oferta (energía, fertilizantes).
-
Contagio y co-movimiento:
- En ventanas de alta
avg_abs_corr(vercmo_rolling_network_metrics.csv), la red se densifica, con: - Energy y Fertilizers actuando como transmisores clave,
- Agricultura y Softs recibiendo shock vía costes de insumos (fertilizantes, energía).
- Esto es coherente con regímenes inflacionarios de commodities donde múltiples complejos suben a la vez.
- En ventanas de alta
-
Commodity supercycles:
- La combinación de:
- Tendencias de precios normalizados por décadas (ver gráfico de precios),
- Persistencia en volatilidad y clusterización,
- Correlaciones elevadas en ciertos intervalos largos,
- es consistente con superciclos en metales industriales y energía (aunque la validación exacta de superciclos requeriría análisis de tendencia secular adicional).
7. Archivos clave para tu trabajo / notebook reproducible
Visualizaciones (PNG, dark-mode institucional):
- Heatmap de correlaciones full sample:
- Red de spillovers (ventana de alta correlación):
- Precios normalizados (por grupo):
- Distribuciones de retornos:
- Drawdowns:
- Clustering MDS:
Informes y scripts:
- Executive report (resumen ejecutivo en Markdown): Download file
- Informe de spillovers: Download file
- Notebook/script reproducible del pipeline (estructura modular en Python): Download file
8. Limitaciones y próximos pasos sugeridos
Limitaciones / supuestos:
- Clasificación por grupo es rule-based y puede requerir ajustes manuales para algunos códigos WB menos estándar.
- Modelos GARCH se estiman con distribución normal; podría mejorarse con Student-t o skewed-t.
- Los resultados de superciclos e inflación se infieren por cambios de volatilidad, co-movimientos y redes; un análisis estructural de tendencia de muy largo plazo podría refinar estas conclusiones.
Próximos pasos que te propongo:
- Ajustar universo de commodities de interés (e.g. energy-heavy vs agri-only) utilizando
cmo_commodity_inventory.csv. - Refinar modelos GARCH sobre un subconjunto clave (Brent/WTI, Copper, Urea, Wheat) con:
- Distribuciones heavy-tailed,
- Inclusión de dummies de crisis para capturar breaks estructurales.
- Construir índices sintéticos:
- Índice de costos de fertilizantes,
- Índice de energía de input agrícola,
- Índice de metales industriales, y luego modelar spillovers entre índices en lugar de commodities individuales.
- Vincular resultados con inflación macro:
- Extender pipeline (sin yfinance, pero con datos macro externos si los aportas) para conectar los regímenes de alta volatilidad y alta correlación con episodios de inflación global y policy tightening.
Si quieres, en el siguiente paso podemos:
- Focalizar en un subconjunto de commodities (por ejemplo, solo Energy + Fertilizers)
- O profundizar en comparación cuantitativa entre modelos GARCH/EWMA
para una o dos curvas específicas (p.ej., NGAS_US, UREA_EE_BULK) con
métricas de forecast más detalladas.